



Mastering Product Discovery - Quantitative Discovery
Everything you ever wanted to know about Quantitative Discovery with stories from Lyft, Patreon, Facebook, Slack and more.


Hi there, it’s Adam. 🤗 Welcome to my weekly newsletter. I started this newsletter to provide a no-bullshit, guided approach to solving some of the hardest problems for people and companies. That includes Growth, Product, company building and parenting while working. Subscribe and never miss an issue. I’ve got a podcast on fatherhood and startups - check out Startup Dad here. Questions? Ask them here.
In this newsletter I was joined by Behzod Sirjani; someone whom I consider a fantastic researcher and teacher of research methods.

Behzod is a research consultant and advisor. He currently runs Yet Another Studio, where he partners with early stage companies to build effective research practices, working with everyone from two person teams up through companies like Figma, Dropbox, and Replit. He is also a program partner at Reforge, where he built both “User Insights for Product Decisions” and “Effective Customer Conversations,” a venture partner at El Cap, and an advisor for TCV’s Velocity Fund.

Note: This is a very long newsletter. It will definitely get cut off in your email client. Feel free to check it out on the mobile app or on web.
In the first part of this series I wrote an introduction to Product Discovery – including some of the common misconceptions about what discovery is and isn’t as well as a story about effective product discovery at Patreon.
Today, with the significant help of Behzod Sirjani, we dive deep into Quantitative Discovery methods. These are the methods that involve numbers and counting things. One of my biggest pet peeves with the “You’ve got to do discovery!!” crowd is that they don’t tell you how or provide examples of what effective discovery looks like. We aim to solve this in today’s newsletter and create a canonical resource for Quantitative Discovery methods.
On the product discovery continuum introduced in Part 1 the quantitative methods are on the right hand side.
Here’s what I said in the prior post about discovery more broadly:
At its core the role of discovery is to understand. Understanding customer problems and opportunity areas, understanding and developing opinions on what to build, and even understanding how to build it. It is rooted in the idea that building a fully scalable product solution (product, feature, service, etc.) is expensive, time consuming and uncertain.
The roadmap for this series:
Part 2: Quantitative Discovery Methods ← This post
Part 3: Qualitative Discovery Methods (coming in 2024!)
What is Quantitative Product Discovery
Quantitative product discovery (QPD) is a process by which you use quantitative data to inform decisions about product development. In QPD you use metrics, statistical analysis and numerical data to understand the needs of customers, trends in the market, and the potential impact of new features and products.
QPD is especially useful when you and your organization believe that decisions should be based on data rather than intuitions or assumptions. Quantitative discovery is an excellent complement to the qualitative methods we’ll discuss in Part 3. It is very useful for pointing you in the right direction for further investigation and can tell you what, how much, and how often something is occurring.
Some forms of QPD, like experimentation, are the gold standard in testing hypotheses and measuring the impact of changes to your product. But not all companies can run experiments effectively due to traffic limitations or technical and organizational constraints. Organizations that trend towards a lower tolerance for risk tend to rely more on quantitative product discovery and the scalability of collecting quantitative data (assuming you have the users) is much easier than qualitative.
An overreliance on QPD can be harmful and shouldn’t be used in every situation. As the prevalence of experimentation has increased I hear a lot more PMs absolve themselves of tough, opinionated decisions opting instead to run an experiment for everything. I don’t like this trend. QPD, and specifically experimentation, only works when you have the ability to collect a meaningful amount of statistically significant data which not every company can do. When I was at Patreon, my team member Tal Raviv wrote a great article about when you shouldn’t over-rely on QPD in the form of AB testing.
One of my favorite quotes from this article:
“A/B testing is not an insurance policy for critical thinking or knowing your users.”
The goal of this newsletter is to show you the situations in which QPD is highly useful, how to leverage the different types of QPD, and where over-reliance is harmful.
Here’s a summary table with some of what we’re about to discuss.
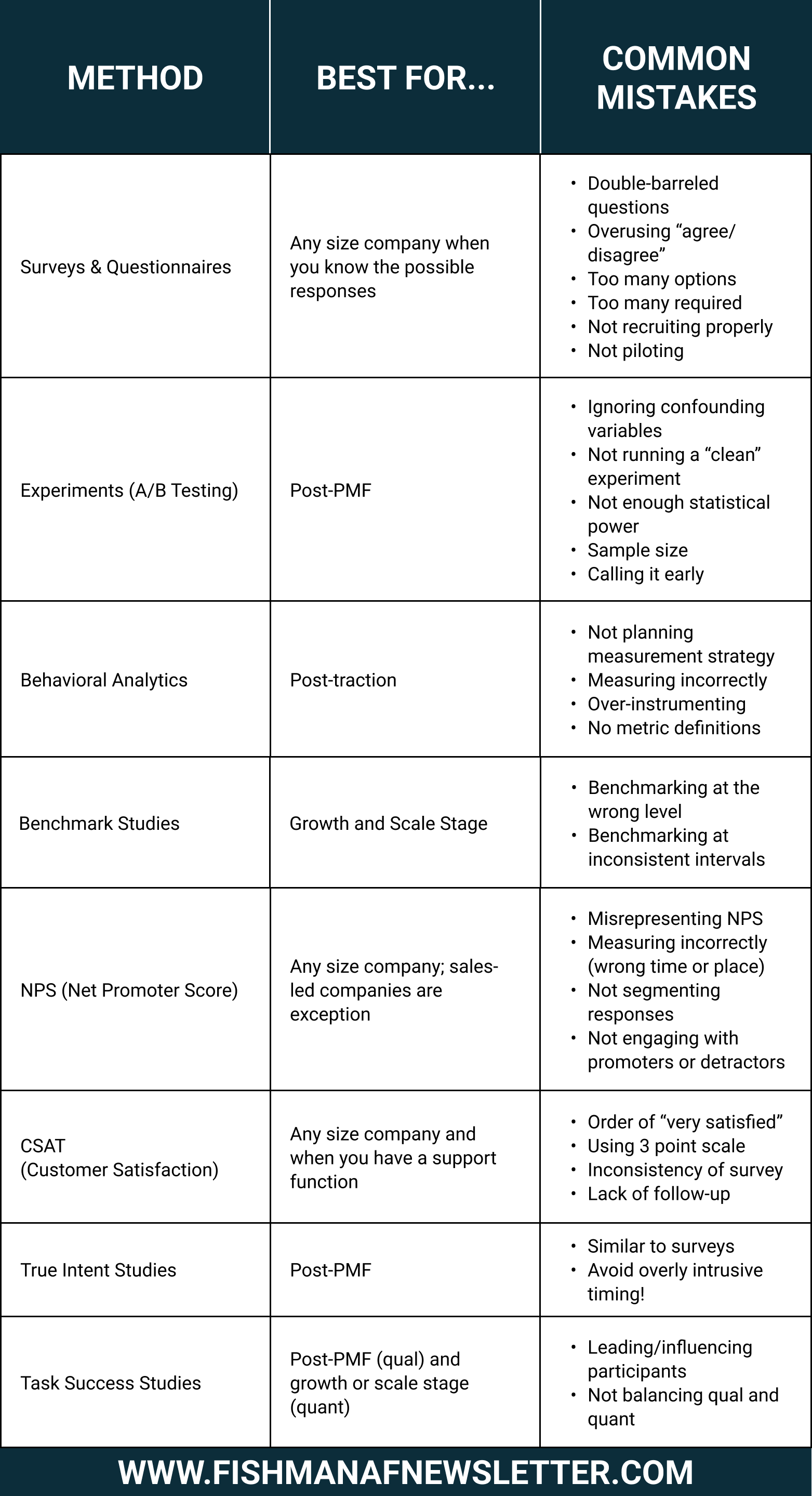
Types of Quantitative Product Discovery
To start, here is every type of quantitative discovery that Behzod and I could think of (if you have more you think we should add, please let us know!):
Surveys and Questionnaires ⭐
Experiments / AB and Multivariate Testing ⭐
Analytics and Usage Data ⭐
Cohort Analysis
Funnel Analysis
Clickstream Analysis
Heatmaps
Benchmark Studies ⭐
NPS (Net Promoter Score) ⭐
CSAT (Customer Satisfaction) ⭐
True Intent Studies ⭐
Task Success and Time-on-Task Analysis ⭐
Error Rate Analysis
Eye Tracking Studies
Biometric Analysis
We’ll take the ⭐ items from this list and discuss:
What it is and when to use it.
What size/state of company you should be able to leverage this
How to do it successfully
Common mistakes to avoid
Artifacts and templates you can leverage
Stories of successful execution and outcomes
Software that you can leverage to help you with it
Surveys & Questionnaires
Let’s start with a straightforward one. The almighty survey!
What is a survey and when should I use it?
Although the words “questionnaire” and “survey” are used interchangeably they actually mean different things.
A questionnaire is a set of questions that gathers answers from a set of respondents. A survey is a data collection method that uses a questionnaire to gather data which will be analyzed statistically to make generalizations about a given population. So basically the questionnaire is the thing that you use to ask questions; the survey is how you analyze results.
Almost everyone (Adam: guilty) says they are “sending out a survey” but few people follow survey design best practices and actually apply statistical rigor to their responses.
Both surveys and questionnaires are useful when you want to ask a set of questions and you have a reasonable sense of the possible responses from your participants. Surveys and questionnaires are not great when you do not have confidence in how your participants will respond, when you want to ask a lot of questions, or when you have a large number of open-ended questions. Surveys are also not ideal when you cannot effectively sample from your target population (and thus are unable to generalize your responses).
The most common types of questionnaires/surveys in modern product development are:
The Intercept Survey
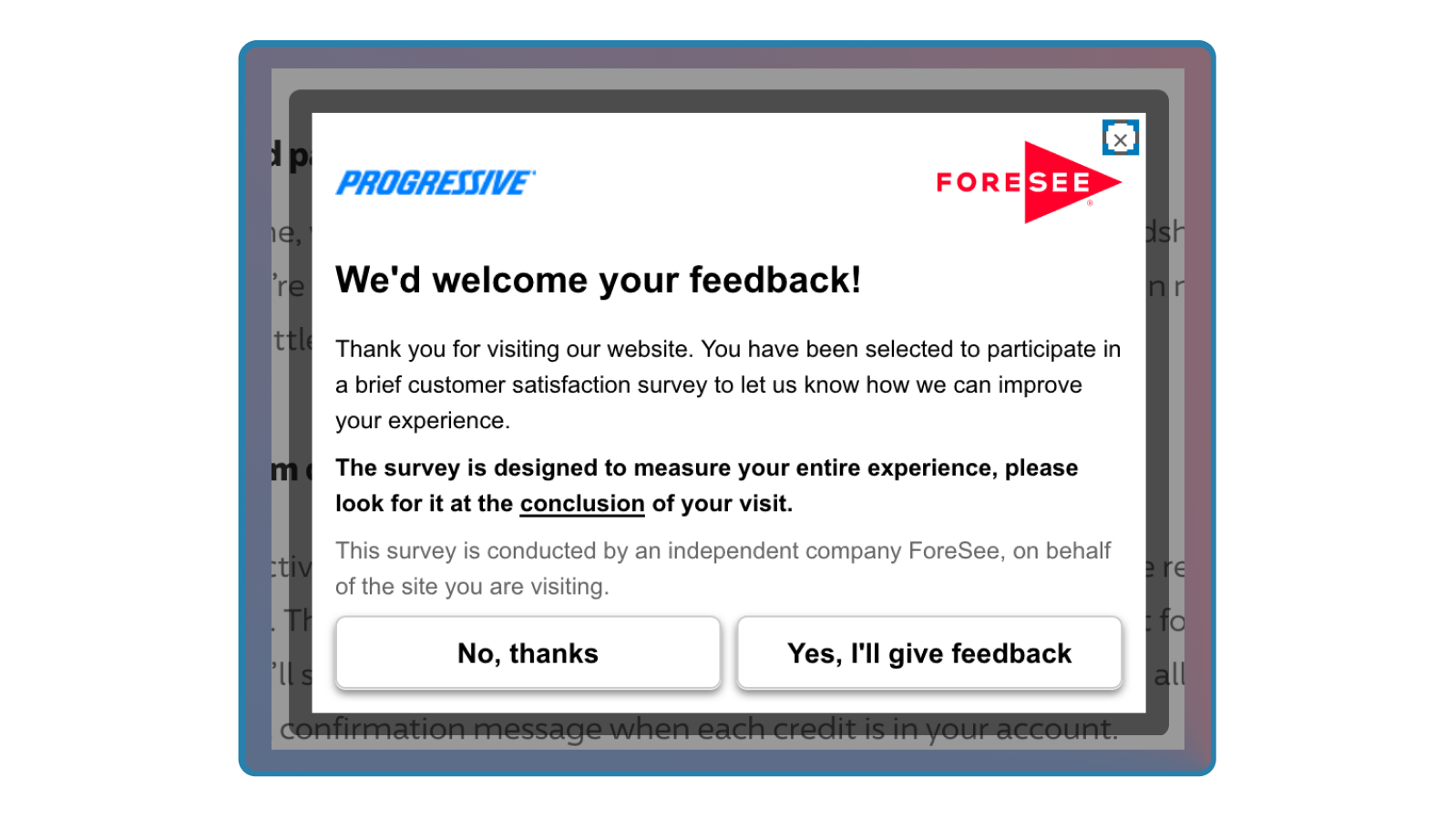
An intercept survey is a modal or dialog that intercepts the user while they are completing or just have completed an action. These are often short (1-3 questions) and are triggered based on a user's behavior. (Adam: the banking industry is notorious for over-intercepting me with these at the absolute wrong time).
Tracking Surveys
Tracking surveys are run at regular intervals (i.e. quarterly) to track measures like user sentiment, satisfaction, perceived product quality, brand sentiment, etc. from your customers. These are often the longest surveys that an organization will send out and are useful in providing visibility into trends over time.
Feedback Surveys

Feedback surveys are typically sent out after a customer has an interaction with the sales or customer support team about the experience and resolution of their issue. These tend to be shorter in length and meant to evaluate the service that was provided to them. Ever sit behind an 18-wheeler on the highway with a bumper sticker that says “How’s my driving?” That's also a feedback survey.
One-Off Surveys
Occasionally, teams will want to gather feedback about a specific set of topics where a survey is the best research approach. These one-off surveys are very tailored in terms of questions and audience and typically ladder up to informing a specific set of decisions within a product area (e.g. a platform team sending a survey to developers about their current APIs). These one-off surveys are often paired with qualitative research methods and/or evolve into tracking surveys over time (e.g. the aforementioned survey evolving into a company’s developer satisfaction survey).
In the example I used in Part 1 at Patreon, I leveraged the one-off survey as a follow-up to a set of qualitative observations from creator pages. This worked well because I wanted to ask a set of questions and had a reasonable sense of the possible responses from the participants.
What size and state of company should you consider leveraging surveys?
Anyone can leverage a questionnaire since it involves sending (mostly) closed-ended questions to a group of people. However, when you send a questionnaire, you should treat this data as directional since you will not be able to generalize it to the broader population if you do not have a sufficient sample size.
Companies cannot leverage surveys effectively until they have access to a meaningful sample of the population they care about. Both Qualtrics and SurveyMonkey have sample size calculators that help you understand how many people you will need access to given the size of the population you want to generalize to. You will also need to factor in your typical response rate, which is often 5-10% of those you contact. For example, if you need to get 100 responses you’ll likely need to reach out to between 1,000-2,000 people.
How to leverage surveys successfully?
We’re going to walk how to use surveys generally and then dive into specifics about each different type.
Step 1: Identify Your Target Audience
One of the most important things to figure out is who you are surveying. Asking the wrong people the right questions is a recipe for disaster. The target audience will vary based on the type of survey. An intercept survey will be targeted at people who take a specific action versus a tracking survey which could go out to all of your customers. An easy way to start is to write out in plain language the kind of people you’d like to respond to the survey (i.e. “enterprise customers” or “people who have just completed the onboarding flow”). From here you can identify what attributes, behaviors, or experiences matter about your target audience.
The next thing to do is size the available population. You want to figure out how many potential participants exist so that you can determine how many of them you need to reach out to in order to have statistically significant responses. You want to do this with each audience segment you care about getting responses from and drawing conclusions about (e.g. if you care about customers on two different plan types like pro and enterprise you should size each of them individually).
Step 2: Designing the Survey Instrument
Work backwards from the kind of data you want to gather. You can start by drawing the charts you’d like to make from the data or writing out the types of conclusions you’d like to reach (e.g. “40% of respondents said the primary reason they chose our product was price”).
For each of these charts or conclusions, draft 1-2 questions that you can ask so you can gather the necessary data. The reason you may need two questions is to represent two variables. For example, if a conclusion you want to draw is that “40% of our satisfied customers care about XYZ” then you need to understand both who is a satisfied customer and then what they care about.
Organize your questions in a logical flow. While you need the order of the questions to make sense to the participant, it’s often helpful to put the most important questions toward the front and the demographic questions at the end. This is because every question is a tax on your participant’s energy. You want to put the cognitively challenging questions up front and the easier ones later on. The exception to this is screening/qualifying questions. If you need to appropriately segment or bucket respondents then those will have to appear earlier in the questionnaire.
Finally, evaluate the length of the survey/questionnaire and consider what makes sense given where it will be shared. Look back at the types of surveys above for guidelines.

Step 3: Programming & Piloting Your Survey
Once you’ve drafted your survey, you should build it out in whatever tool you are going to use (e.g. Google Forms, SurveyMonkey, Typeform, etc). As you build this out, make sure that all of the logic is programmed correctly. For example, if you have a different set of questions for new versus tenured users, make sure that selecting the right option gives you the right set of follow up questions.
You should also pilot your survey with someone who is not you (and ideally one degree removed from whatever you are working on). This helps you get outside of your own head and ensure that your questions make sense, are using only essential jargon, and do not feel overwhelming or invasive to the participant.
Finally, you should test how your survey works on both desktop and mobile environments, assuming you are distributing it that way.
Step 4: Distributing Your Survey
The way you distribute a survey depends on the kind of survey you are sending. If you’re using an intercept survey, your distribution is likely in-product based on a trigger. If you’re sending a tracking survey, you’ll likely distribute it via email to potential respondents.
No matter what method you choose, you should test that your distribution works (i.e. send yourself a test) and use a phased roll out surveys with larger audiences. This could look like sending the survey to 10% of your potential respondents and monitoring email bounce, open, and response rates for an hour before sending out the rest of the invites.
Testing across all the dimensions mentioned above is very important. If you mess up survey delivery you’ll greatly hamper your response rate and analysis. Tread lightly!
What are common mistakes to avoid with surveys?
As straightforward as we make it seem there are still several pitfalls with questionnaires and surveys.

Avoid double-barreled questions
A double-barreled question measures two separate things at the same time (i.e. “How fun and easy was signing up for our product?”). This is a mistake because the attributes are independent of each other and should be asked about separately. In this example, it could have been fun and easy, fun and difficult, not fun and easy, or not fun and difficult. It’s much easier and less cognitively taxing for your participants to ask about each of these items separately and then triangulate the data after the fact.
Overusing “agree/disagree” questions
While agree/disagree questions are easy to write, they’re not ideal in many cases because they abstract what is being asked into a single metric (agreement). Very often we use agree/disagree questions when we can’t think of all the different answer options that a question should have. Instead, we choose one that we like and ask people to agree or disagree. As an example, we could ask you: “To what extent do you agree or disagree with the following statement: ‘The FishmanAF Newsletter is a good use of my time.’?” With answer options from strongly disagree to strongly agree.
If we’re running with the idea that the FishmanAF Newsletter is a good use of readers’ time (Adam: of course it is, dammit), then a better way to phrase that question may be: How often is the FishmanAF Newsletter a good use of your time? With answer options like never, rarely, sometimes, often, always. But if we’re trying to evaluate whether or not the FishmanAF Newsletter is a good use of your time, we’re better off asking about how valuable it is and which parts contribute to that value. (“Which of the following types of content from the FishmanAF Newsletter have helped you in your current role?” with answer options like “frameworks and templates,” “interviews with experts,” “hot take alerts,” etc).
By breaking this one question about the newsletter being a “good use of your time” (i.e. valuable) into two different questions (how valuable and what parts are valuable) we actually have better, more actionable data from respondents.
Including too many answer options
Responding to survey questions is cognitively taxing, no matter how well written they are. In most cases, survey questions only need a handful of choices to provide respondents with options that are mutually exclusive and collectively exhaustive (MECE). There are times, however, where you may be asking about a participant’s job role or industry that requires more than 10 choices. Limit the number of these kinds of questions that you use.
Making every question required
One of the cardinal sins of survey design is making every question required. While you may feel like every question is absolutely necessary, research has shown (Adam: pun intended) that this decreases overall response rates. Even if you’re doing your best to keep the survey short and ask essential questions, only mark the most critical questions as required. You may be surprised at how many people answer them all anyway.
Not recruiting properly
If you’re sending a survey, you should care about generalizing your responses to a given population, whether that’s a specific audience segment or all of your customers. Make sure that you’re recruiting enough of the right people so that you have the statistical significance to make the claims that you want.
Not piloting your survey
It’s very easy to write your survey and just send it out. But this is risky. Make sure that you test your survey on any platforms that participants may use to respond, such as mobile and desktop. Also, confirm any survey logic works as expected before sending out your survey. There is nothing worse than a broken survey for destroying your response rates or rendering the results useless. Piloting also gives you a chance to time how long it takes to answer the survey (and we’d recommend asking someone else to fill it out so you have a more accurate assessment).
What artifacts or templates exist that I can leverage to help me get better at surveys?
Here is a great example of product and marketing survey questions from Jack McDermott at Chegg. And here is a screening survey created by Behzod for a stealth startup.
What are examples of surveys in action?
Developers on Slack
In the early days (2015-2017) of the Slack platform the product team had a strong connection to the developer community. As the platform and number of developers grew, it became harder to keep track of everything being built and maintain those relationships. To make sure we continued to have a pulse on our developers, we launched a survey to understand how supported our developers felt, areas that Slack could provide better education and resources, and get visibility into what else developers wanted from Slack. This was especially important because we had website traffic and usage data for a lot of our resources, but no feedback on how helpful they were.
Because this was one of the first times running a survey like this, we intentionally asked more questions than we thought would be reasonable. Some of the things we asked included:
Which languages developers were building apps in
Whether they were building solo or with teams
Which Slack resources they had engaged with and how helpful those resources were
Common challenges they ran into building on Slack and how they tried to resolve them
Whether or not they had engaged with anyone at Slack and how those engagements went
While some of these questions would likely be a better fit for interviews (especially if we wanted specific examples) going broad like this helped us get an overview and identify which areas we should track on a regular basis. We eventually did that via an ongoing, developer tracking survey (more on tracking surveys later).
One of the main outcomes of doing this survey was clarity in how the product, developer relations, and support teams could prioritize future resources for the developer community—both in terms of the kinds of content that developers wanted (e.g. tutorials, guides, etc) as well as the actual topics themselves. This survey also gave us a sense of what the meaningful differences were in our developer audience. Segments could be what you were building, how you were building, or why you were building on Slack. We ended up turning this data into a set of questions that we’d use in subsequent developer surveys to effectively segment our audience.
Facebook and Video
When Facebook was ramping up its investment in video content, the platform still had a lot of videos posted that were links to YouTube. This meant that it was challenging for us to determine what kinds of content people liked and understand how long and in what ways people were engaging with video content. We decided to do a large scale survey (3,000+ participants) of a representative sample of our US audience to understand a broad range of measures:
What kinds of video content people watched
What devices they watched that content on
Where they were when they were watching videos
How long the video content was
Whether they were browsing or searching for videos
Who they shared that content with
This was a massive undertaking and normally it would be the kind of thing that we’d much rather have usage data for than be asking people to self-report. But capturing usage data was impossible at the time, so we felt that a survey would give us a directional sense of people’s perceptions. We could then triangulate that with other data we had internally on native video and video consumption data we could get from industry reports.
We were aware that watching a show on Netflix was much different than the short form videos people would consume on Vine or YouTube. We asked about the kind of content they had viewed in the last week and then from there asked specific follow up questions for each kind of content. This allowed us to reduce the cognitive burden on survey participants even though it resulted in a much more complicated survey design.
Although peoples’ stated preferences and actual behaviors may differ, getting a sense of what people watched, where they were, and when they were watching helped us prioritize different forms of video content to bring onto Facebook. Along with other data we had, this survey also shaped the explorations we did for the video viewing experiences across different devices and how we ranked video content in feed.
What software can you leverage to help you with surveys?
While not an exhaustive list (Adam: don’t @ me if your company isn’t listed below) there are several tools that you can use to facilitate running a survey or questionnaire. They range in cost and complexity from “free” and “basic” to “expensive” and “advanced.” The good news is that most survey and questionnaire tools have some form of entry-level, free or freemium offering. PLG for the win!
Here is a non-exhaustive list of tools you can use:
Google Forms
Microsoft Forms
JotForm
Typeform
SurveyMonkey
OpinionX
Zoho Survey
Sprig
Qualtrics
I have used many of these tools at different times and with companies of different sizes and stages. If you’re just getting started I recommend something like Google Forms, Typeform or SurveyMonkey. If you’re approaching significant scale you’re probably at the higher end of SurveyMonkey or Qualtrics. These aren’t hard and fast endorsements, just some directional advice.
Experimentation: A/B & Multivariate Testing (MVT)
Experimentation is a wonderful thing. It helps us avoid biases like overestimating success, overestimating potential and revisionist history by inflating our historical success. But there are definitely downsides to over-relying on experimentation. Let’s dig in!

What is an experiment and when should I use it?
Experimentation via A/B testing is comparing two or more versions of a product or feature to determine which performs better based on specific metrics. Multivariate testing, or MVT, involves testing multiple variables simultaneously to determine the best combination and interactions between tested elements. Remember that experimentation is a discovery tool and like many other tools we discuss in this article it is important to know how and when to use it for maximum effectiveness.
A/B tests are a great tool to use when the best way to decide how to move forward is through observing actual customer behavior, at scale, in a controlled environment. As people who build products, we often have skewed ideas about what will be most useful for the people that we’re trying to serve. A/B tests offer us a way to gather quantitative, behavioral data from a specific group of customers over a period of time to give us more confidence in a specific direction or design approach because we’re able to control for a set of variables and conditions.
When paired with qualitative discovery methods it helps us bridge “what people say” with “what they actually do.”
What size and state of company should you consider leveraging experimentation?
Any company can leverage experiments, assuming they have the ability to segment their customers and deliver different versions of the product to enough people to have statistical significance. If you’re unable to provide variations of a product or unable to segment users confidently, A/B testing is not an ideal approach. If you’re pre product-market fit you’re probably not running a lot of quantitative experiments because you just don’t have the data (or the time).
How to leverage experimentation successfully
There are an almost infinite number of resources on experimentation so I (Adam) won’t try to regurgitate absolutely everything you need to know to do this effectively. Instead, I’ll direct you to a few of my favorite places and then summarize an approach below.
Two of the most in-depth courses on experimentation are Ronny Kohavi’s course on Accelerating Innovation with AB Testing and Elena Verna’s Experimentation and Testing course on Reforge. But in case you don’t have thousands of dollars to spend (you are reading a free newsletter after all), these steps should help you:
Define your hypothesis
Define your test and measurement strategy
Prioritize your experiments
Build your experiment
Analyze your experiment
Step 1: Define your hypothesis
The first step in running an A/B or multivariate test is to define your hypothesis. This is often written in a statement that outlines how a change in your product will result in a change in behavior or outcomes (which should be ideal to the business), such as “We believe that [doing a thing] will result in [change in behavior as measured by this metric].” A hypothesis is not a guess at how something will perform. Done correctly, an effective hypothesis leads to a clear set of learnings.
If you’re clear on the problem that you are trying to solve then generating the hypothesis is much more straightforward.
For example:
Problem: We have too many people who open the Lyft app and don’t request a ride.
Hypothesis: We believe that passengers don’t request rides because they don’t see enough cars on the map.
Some other examples of clear hypotheses:
We believe that prospective customers are not converting because they think our price is too high.
We believe that users are not signing up for the service because they don’t understand our offering.
Note that these should not be random. Your hypothesis should be informed by existing data or insight. In other words, what other discovery evidence do you have that supports your hypothesis?
Step 2: Define your test and measurement strategy
Once you have a clear hypothesis, it’s important to define your test, your success metrics, and what could go wrong with your metrics (Reforge calls these “tradeoff metrics”). Identify all the potential outcomes from your test to ensure you can confidently measure those outcomes. Without the ability to measure what happens, running the test is useless. You won’t be able to draw any conclusions!
A large part of defining your test is the experiment design. This includes the trigger for the experiment, platform for targeting, eligibility criteria, assignment criteria and the response (and tradeoff) metrics. Here’s a handy table for remembering these, from this post.

You’ll also want to define the actual solutions or variants that you’ll be testing as well as the runtime of the experiment—which you can calculate after identifying the minimum detectable effect (the smallest improvement that you can confidently say is not just happening by chance).
When defining your solutions you want to avoid being subtle in your changes and also keep it simple. Subtlety seems like a good idea at first so you don’t rock the boat, but it will be really annoying when your experiment is so subtle that it doesn’t lead to a conclusive result of any kind. Keeping it simple is important because the whole point of experimentation is to use less resources to learn. A complex experiment could render that point moot.
For an experiment document template including all of these elements of how to run a successful experiment in a lot more detail check out this newsletter I wrote: Creating an Experiment Document.
Step 3: Prioritizing
There are a lot of debates and frameworks on prioritization methods. I think a lot of this is just hot air because when it comes to prioritization having a consistent system is better than no system at all.
In any prioritization system you should make sure to include elements of the following:
How difficult is this to implement?
How likely are we to learn something meaningful from this?
How successful could this be?
All product discovery comes with a cost and experimentation happens to be one of the most costly because it leverages more resources and often the most expensive resources. Your ROI calculation for an experiment is then: how much will we spend to learn something meaningful about our users? If you can’t create clarity around that then you’re not going to make much progress.
Step 4: Building
How you build your experiment will depend a lot on tooling (below), team size, and resources involved. Here are a few “building” areas to watch out for:
Overbuilding. This is an experiment for discovery (learning) purposes. It is not the fully-finished, infinitely scalable, product feature that it could become eventually. The thing has to work, but it doesn’t have to be the Sistine Chapel.
QA the experiment. If set up properly, even a failed experiment (metrics-wise) will teach you something meaningful. But a poorly-setup experiment is a waste of time or worse: it could cause you to draw the wrong conclusions. Common vectors of poor setup are the randomization unit, eligibility criteria, and data collection for results. If you’ve never used a particular tool or tested in an area of your experience before I recommend an A/A experiment (no change in what people see) to make sure that you’re not randomizing/bucketing people incorrectly and collecting data properly.
Step 5: Analyzing
Don’t equate analysis with successful moving of the metrics. That’s a wonderful outcome, but remember we’re trying to learn with this discovery tool and in the Patreon example below we learned a lot despite the metrics not moving much (at first). The most important outcome of your analysis is that it causes you to do something different as a next step. I like to equate experimentation to the raptors testing the fences in Jurassic Park. With each zap they’re learning something. The difference is that with these experiments the engineers don’t eat you. I hope.
Outside of the obvious success or failure from a metrics perspective the most important analysis criteria are 1) what was the scale of success/failure and 2) why?
Scale matters because it gives you a sense of just how accurately your results tracked your hypothesis. This can help with subsequent revisions on the hypothesis and build confidence in future hypotheses. For example, if your experiment was a metrics failure and it failed by a country mile then you might be more likely to question whether you should continue following this hypothesis with different solutions. If it succeeded in the opposite direction you might be more excited to continue following that hypothesis.
Underlying all of this is the “why.” What is it about the psychology of your users that caused them to behave in the way that they did? This is also where qualitative discovery can complement experimentation.
What are common mistakes to avoid with experimentation and a/b testing?
Ignoring confounding variables
A confounding variable is something that influences the outcome of a test and is outside of the parameters of what’s being studied. Examples of commonly ignored confounding variables include:
Existing product usage experience
Income/purchase power
Customer demographics
Seasonality
The best way to account for confounding variables is through your study design. For attributes like demographics or product usage, make sure to randomize or segment your audience with these in mind. For aspects like seasonality, acknowledge them up front and be clear about how generalizable your results are.
For example, if you broadly segment “new vs. existing” users and then try to generalize insights on your “existing” segment you’ll have wide variations between those who are loosely engaged (but not new) vs. your power users who are highly engaged. You’ll need to control for this in the analysis portion or through proper, up-front segmentation such as creating a treatment group of power users.
With seasonality, imagine you’re a direct to consumer retailer running an experiment around Black Friday. Would those same results and insights hold in the middle of July when customers aren’t in the holiday spirit?
Not running a clean experiment
Running a successful A/B test requires you to limit the difference between the test and control conditions to just that – the variation that you’re testing. Aside from the different design/feature/experience, everything else should be held equal (or have an equal chance of being true). Unfortunately, people very often layer product experiments on top of product experiments, which reduces the ability of an A/B test to conclude anything.
One example of this might be testing the layout of your homepage while simultaneously testing the elements of that same page. Or testing where you ask people to sign up for your service with the existence of a free trial. Both of these may seem like hypothetical scenarios, but I’ve seen them each play out (with poor results) at different times. And yes, you can create combinations of changes but the more variations you have the greater the sample size you’ll need.
Not having enough statistical power
Statistical power is the ability of a study or experiment to detect a real effect when there is actually an effect to be detected. If this is low, then you run the risk of missing a real effect. In other words, you might fail to reject your null hypothesis (there is no difference between the groups) even though the alternative hypothesis is true (there is a difference).
Sample size
You’ll notice that I didn’t say “insufficient” sample size here. While it is true that not having enough users participate in the test can render the experiment statistically invalid it is equally true that too much sample size can waste precious time.
Calling an experiment early
It is important to understand in your experiment preparation how long you need the experiment to run in order to detect a meaningful result. A common mistake people make is “peeking early” at the results and getting people excited (or disappointed) early on. It is important to monitor results to make sure they’re not causing significant damage to the business, but definitely don’t tell the CEO about results you’re excited about before they’re significant. It could come back to haunt you. Not that I (Adam) have ever done that before of course… 👀.
What artifacts or templates exist that I can leverage to help me get better at experiments and a/b testing?
Our pal Ben Williams has an excellent artifact that he leverages in his advisory practice; check it out here. I (Adam) also shared my end to end experiment process and template in a previous newsletter. And Fareed Mosovat has an example of a template from his time at Slack. If you’re looking for some guidance on how to prioritize experiments, Matt Bilotti (formerly from Drift) provides this overview from his ~7 years there.
What are examples of experiments or a/b tests in action?
If you remember that experiments are a discovery tool and that the role of discovery is to understand then let’s look at an example from when experimentation caused us to better understand our purchasing experience at Patreon.
Patreon’s Checkout Experience
When you’d like to become a member of a creator’s Patreon community you would go through an eCommerce-like checkout experience and pay them a recurring subscription fee. This changed relatively recently with the introduction of free community features, but for the period of time I (Adam) was there (2016 - 2020) free communities were something we talked about but hadn’t implemented yet. So to the checkout flow you go!
Like any checkout experience, there was a significant drop off from starting to finishing the process. We hypothesized that this was related to the experience of checking out—our checkout was fairly non-standard at the time and it lacked many of the “normal” eCommerce best practices. Specifically we thought that adding in many of these elements (trustworthy symbols, context on the purchase, membership tier clarity, etc.) would improve the conversion rate through the checkout.
In a period of ~one quarter we ran between one and two dozen experiments on the checkout experience. From a metrics perspective, the vast majority of these failed to reject the null hypothesis; they didn’t improve the performance of the checkout. A few did, ever-so-slightly, but nothing trajectory-changing for the company. What we saw was that even if we improved the rate at which users went between two steps of the experience it wouldn’t result in more conversions at the end.
So this was a failure, right? Not exactly.
The series of experiments gave us an important insight: maybe the checkout experience didn’t matter much to a prospective patron.
And this turned out to be exactly correct. By the time a prospective patron made it into the checkout experience they had already made up their mind about paying that creator and becoming a member. The opportunity was actually earlier in the experience: on the creator’s membership page. Changing that page was where the real metrics wins appeared.
The series of “failed” experiments hadn’t really failed because they helped us discover that our hypotheses were incorrect and we were spending time in the wrong area of the product. Much like those raptors, we found the weak spot in the fence!
What software can you leverage to help you with experiments and a/b testing?
There is an abundance of software that you can use to run experiments effectively. As with survey tooling these vary based on your level of sophistication, tolerance (or need) for complexity, available resourcing and cost. I (Adam) have used each one of these tools at some point in my career and I’ve also built and leveraged “home-grown” tools. If you’re just getting started I’d recommend something off-the-shelf for simplicity sake. Your process and what you experiment on will be much more important than the software you use.
Optimizely
Amplitude
Eppo
StatSig
AB Tasty
Split.io
LaunchDarkly
Adobe Target
Unbounce
Behavioral Analytics & Usage Data
Wait, isn’t the entire universe of analytics and data a multi-hundred-billion dollar industry?
Yes.
And wouldn’t it be pretty impossible to cover every corner of it here?
Also yes.
So we’ve done our best!
What type of analytics are you talking about and when should I use it?
When it comes to QPD and analytics in this newsletter we’re talking about using event-tracking tools to track and segment user behavior, such as page views, click-through rates, funnel performance, conversion rates and cohort performance. We are not referring to descriptive analytics tools (commonly referred to as Business Intelligence or BI tools). Think Amplitude, not Tableau.
You should have analytics and usage data for all of your core product flows and company marketing efforts (both organic and paid). All of this data provides a critical map of your world, tracking people throughout their journey from potential customers to becoming active, retained users.

Any product person worth their paycheck is looking at some form of analytics data on a daily basis. It is the tip of the spear in QPD and leads to a lot of the other forms of discovery we’ve covered here and will cover in Part 3.
What size and state of company should you consider leveraging behavioral analytics?
If you're a pre product-market fit company you don’t need a large-scale analytics implementation for discovery purposes. Most of your discovery work will come through customer conversation because you’re still validating your idea and understanding the market. You’ll spend a fair amount of time manually onboarding your customers and you won’t have that many channels that bring them in. There are some exceptions to this—for example, if you have hundreds of customers using dozens of features and want to understand feature usage and retention or if your product has a mechanic (like sharing) that would be helpful to understand quantitatively. Also, observing an asymptoting retention curve for product usage is a great signal of product-market fit.
You won’t have that many users though so you can do the bare minimum at this stage. There’s nothing inherently wrong with implementing event-based analytics at a very early stage; it just might not be the highest-leverage activity that you can do when you don’t yet have a product that people will consistently buy.
Once you’ve turned the corner on product-market fit and this is no longer your challenge you should start instrumenting your product right away. The earlier you do this the more historical knowledge you’ll have. You’ll also immediately have questions like: “Where are users getting stuck in our onboarding process?” or “What usage patterns lead to high-retaining users?” If you aren’t tracking event-based data and behavior across sessions you won’t be able to answer them.
This need will only increase the larger you get so it’s a good idea to try to get it right at an early stage or risk having to redo everything later on. The good news is that almost every analytics company out there has some sort of “startup” program right now and even Amplitude recently released a “free” tier.
How to leverage analytics and usage data
We don’t plan on explaining every nuance of building out your analytical infrastructure. There are plenty of great programs out there like Crystal Widjaja and Shaun Clowes’ program, Data for Product Managers, or Austin Hay’s marketing-focused Marketing Technology program that can do a more comprehensive job of that than this newsletter.
Instead, let’s look at the most common types of analysis that you should be familiar with for QPD.
Segmentation
Even though we may talk about metrics in terms of averages when it comes to analyzing user behavior, segmentation is critical. Segmentation is nothing more than the bucketing and grouping of different users based on certain criteria.
One example of segmentation that can impact user behavior is channel source. How do users navigate my experience when they arrive organically, from a particular paid channel, from a referral, etc.
Another example might be device type—desktop web, mobile app, mobile web, and multi-device users are all different segments that may have meaningful differences in behavior between them.
Still another example could be purely behavioral based. How do users behave after coming into contact with certain features, pages, or parts of the experience.
Pairing segments with the next type of analysis is a really good idea.
Funnel Analysis
This type of analysis shows you how successfully a user moves through a particular set of steps in your experience.
For example, constructing a funnel analysis for areas of your product like the onboarding flow (a critical part of the activation experience and thus retention) or the steps of the checkout process can tell you where you’re losing a significant amount of users. Further segmenting those funnels (device, channel source, geography, etc.) can pinpoint whether it is a particular user type who is struggling.
Cohort Analysis
There are two common types of cohort analysis. The most common type is measuring retention of users. In this case you group users by their date of signup, identify a core action that identifies their activation, and track engagement with that action over a defined time window (weekly, monthly, daily).
The second common type of cohort analysis is feature retention. You can understand the efficacy of a feature by how many people are returning to use it (and how frequently). A lot of people make the mistake of looking only at initial feature adoption, but the true measure of success with a feature (much like your overall product) is whether people return to it after trying it.
Clickstream Analysis
This type of analysis is useful for more exploratory purposes. You probably know what a “clickstream” is, but in case you don’t it’s the sequence of clicks, taps or interactions that a user makes while navigating your site or your app. Most analytical tools will generate some sort of visual clickstream analysis like this:
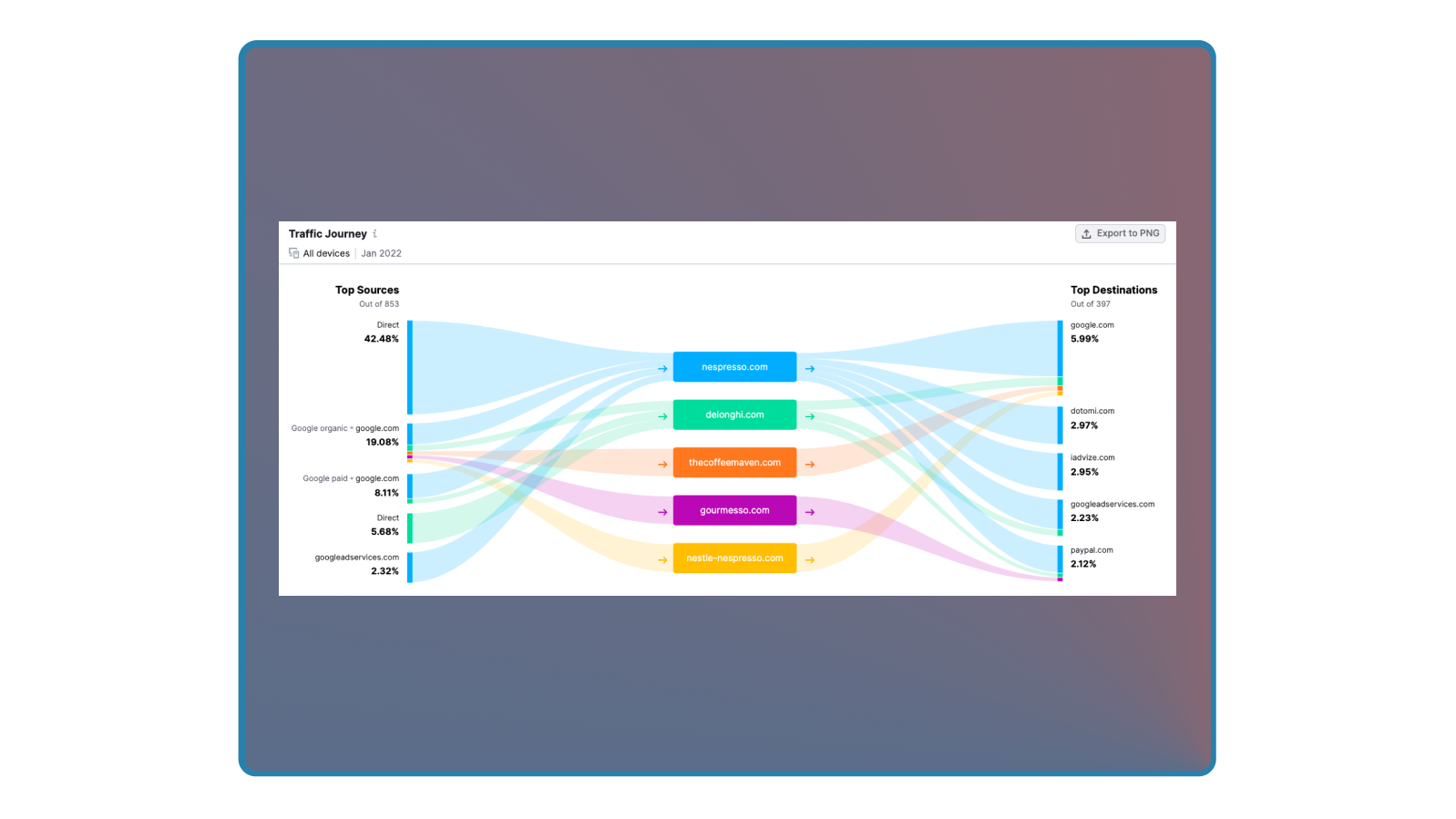
This is useful to understand user behavior when you’re not quite sure what the path that someone takes through your product looks like. It can also show you places where people tend to exit the product. Coupled with segmentation you can further understand how different groupings of users navigate.
Heatmaps
This is another type of behavioral analysis that can be conducted with many of the tools already listed and others like HotJar, Crazy Egg, Clicktale and Fullstory.
Heatmaps show you where users click on a page, how far down they scroll, where they move their mouse, and in certain advanced cases even where people look on a page (although, you’ll need some special gear for eye-tracking heatmaps). They aggregate this data across many user sessions to establish patterns for usage and navigation.
Here is an example:
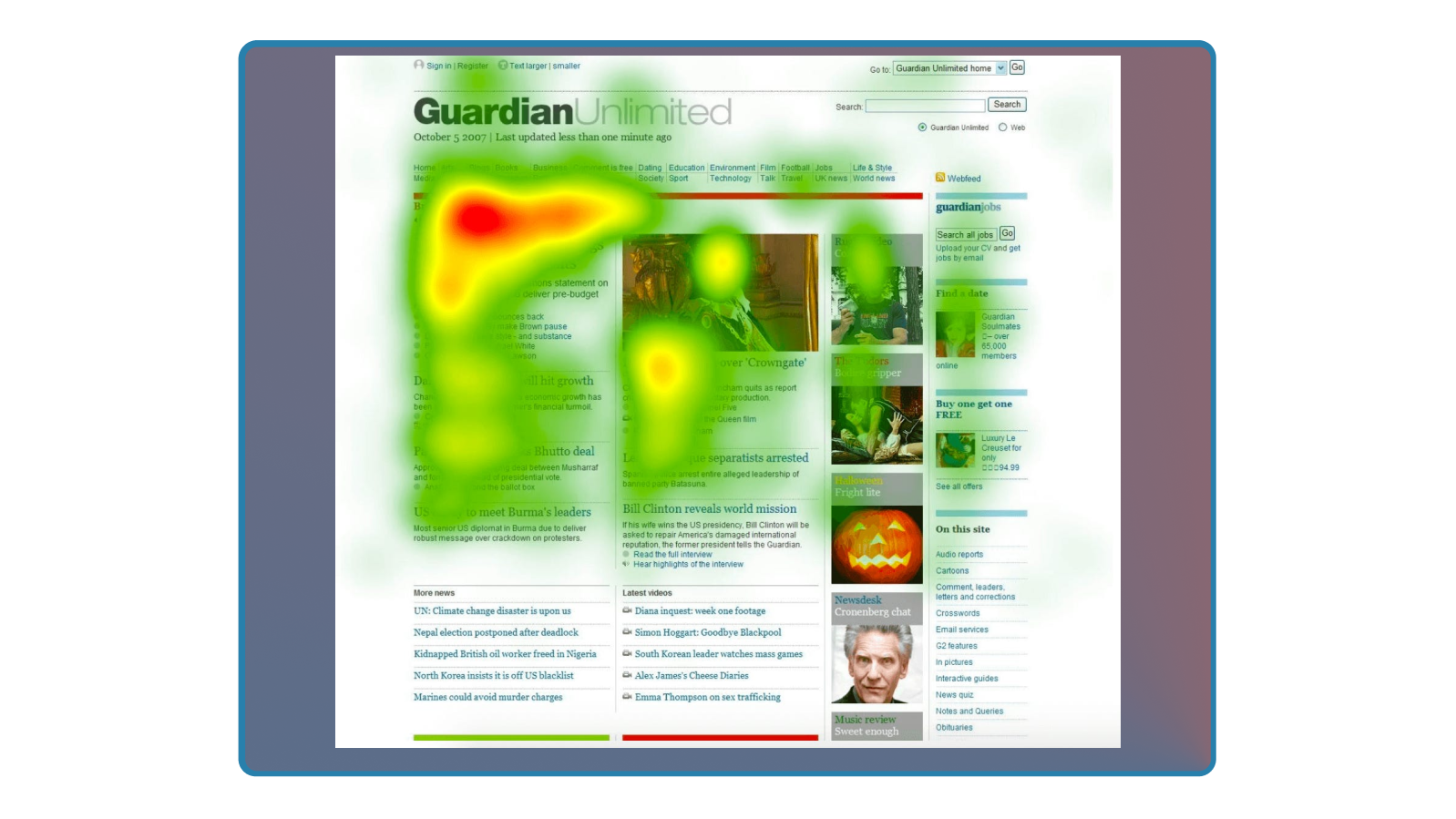
Heatmaps are useful in understanding how a user is navigating, where they’re spending their energy on a page, and whether certain page elements are popular or missed entirely.
What are common mistakes to avoid with behavioral analytics?
Not being thoughtful about what you measure
We’ve seen definitions of “active users” range from “uses the product once per day” to “uses the product once per month.” There are great cases to be made for each of those measurements to be true for a given product or habit loop, but an active user of Uber and an active user of Snapchat are likely measured differently. As you think about the kinds of instrumentation you use and how you define your key metrics, be intentional about the underlying behaviors those metrics represent and the correct way to track them.
Measuring incorrectly
We like to believe that data is objective. It certainly is: it objectively tracks what you define. But it’s easy to measure the wrong thing, give it a metric name, and then take it for granted as ground truth. Be thoughtful about what you measure and how.
Over-instrumenting your product
All instrumentation has a cost to define, build, track, and use. Make sure that you’re instrumenting behaviors that matter and are worth paying attention to. Not every click matters. When you’re just getting started the most straightforward approach is to instrument the “critical paths” of success such as a registration path, a purchasing path, and an invite path.
Not creating metric definitions
For your core metrics, you should create a data dictionary or catalog so you understand what each metric measures and how it’s calculated. At Slack, there was a period of time where we had two different ways to calculate which country a team was from — one way determined the country based on the highest population of people on your team, another way determined the country based on the city with the largest number of people on your team. So if you had 1,000 people spread around the USA and 500 people working in Paris, France, the first approach would say the team was based in the USA and the second approach would say France. 🤦 This knowledge was trapped in the heads of the people who used the tables most, resulting in a few bad analyses until we wrote definitions down.
Note: For more common mistakes and solutions we really like Crystal Widjaja’s article on Why Most Analytics Efforts Fail. She even includes an Event Tracking Dictionary template.
What artifacts or templates exist that I can leverage to help me get better at understanding behavioral analytics?
One of my favorite examples of Feature Retention is Jon Egan’s feature retention analysis on Pinterest’s AR features. For funnel analysis I like Ben Lauzier’s feature funnel analysis from his time at Lyft. And for an example that combines longitudinal conversion data from Amplitude along with funnel analysis, cohorts and attribution channel I think Dan Wolchonok’s Paid Funnel Investigation is fantastic.
For a process on what to do when metrics go awry take a look at Elena Verna’s conversion rate diagnostic process.
Behavioral Analytics in Action - Funnel Analysis
At Patreon we spent a lot of time working on our creator onboarding experience. We built a funnel analysis in Amplitude to understand how creators navigated the steps in the onboarding flow and where the drop off occurred. Studying this led to more than a few interesting insights.
One insight was that we saw significant drop-off at the “Category Selection” step. This was surprising to us because identifying and choosing the categories in which you created seemed relatively straightforward. This drop-off didn’t tell us why the behavior was happening but it did cause us to dig in further and talk with creators. This is often what you’ll experience with quantitative analysis—it points you in the direction of further exploration.
When we dug in we learned that category selection was creating enormous friction because creators weren’t clear on how it would be used and whether it was reversible. Because most creators were familiar with distribution platforms and the almighty algorithm that powered them they assumed that self-selecting a category would somehow impact people’s ability to discover them on Patreon. Since we weren’t a discovery platform this step had no bearing on that. In fact, it was there to provide us more information about the creator and wasn’t used anywhere in the product experience.
Funnel analysis showed us that what we thought was a relatively small decision was actually a very high-friction experience. We ended up removing category selection entirely and eliminating this friction. Instead, we opted to develop our own systems to infer and bucket creators into categories and subcategories without needing to ask for their input. This also proved to be far more accurate and detailed than what a creator would self-select.
What software can you leverage to help you with behavioral analytics?
There is so much software for this. If you’re just looking to get started you can leverage the starter (free) plan from these tools:
Google Analytics
Amplitude
Mixpanel
Heap
Benchmark Studies
What is a benchmark study and when should I use it?
Benchmark studies are when you measure and compare the usability or performance of a product over time or against competitors using specific metrics. These studies should focus on evaluating the end to end experience of core workflows rather than just particular features. A company will often conduct a benchmark study on a regular basis (every 6-12 months) to understand how customers use their product, where customers get stuck or frustrated, and how product changes have been received. This typically provides complimentary data to behavioral analytics.
What size and state of company should you consider leveraging benchmark studies?
You should be post-PMF before you really think about doing a benchmark study. When you have traction and are approaching PMF, you should be focused on the specific aspects of your product experience that will help you achieve PMF and you likely already have visibility into the overall product experience. Post PMF, especially when you start crossing the chasm into adjacent users and use cases, it’s important to take a more holistic look at the product experience on a regular basis. One of the benefits of conducting a benchmark study is visibility into how different customer segments use your product and the value that they get out of it.
How to leverage benchmark studies successfully
One way to think about a benchmark study is as a set of usability studies with different customer segments. You want to evaluate the core product experience or key user journeys with each customer segment and try to recruit a meaningfully diverse set of users.
Here are the steps to run an effective benchmark study:
Step 1: Identify your key customer segments
Think about where there are meaningful differences in your customers, whether that’s based on product offering or usage. You want to identify customer segments that are reasonably homogenous along a key dimension that won’t change (e.g. customers who use your enterprise plan). This enables you to choose tasks that will be applicable for the segment. Some examples of segmentation within B2B could be based on size of company, industry or length of time as a customer. For B2C you could segment by age or location.
Step 2: Define the core tasks you want to benchmark + any segment-specific tasks
While you likely want all customers to do some tasks, certain segments may also have their own specific activities. You want to draft all of these together so that you can ensure each participant isn’t overburdened by the amount of tasks you’re asking them to do. Some benchmarking tasks could include the length of time it takes to complete a transaction (in an eCommerce setting) or ease of navigation (in any setting).
Step 3: Develop a study protocol (conversation guide + usability test plan)
After you have clarity on segments and core tasks, you should build your study protocol, which includes a guide for your conversation as well as the specific tasks you want customers to do. It’s often important to start off with some questions about the customer that will give you context about their behaviors and make sure you’ve segmented them appropriately before you dive into the specific activities. Specific activities will then include the tasks, the order in which you want them performed, and defined metrics of success.
Step 4: Conduct the study
Once you have a plan in place, recruit participants from your key segments and conduct the study. You’ll want to make sure you’ve recruited a representative sample from each of your segments. Before you run the full study it is helpful to pilot the protocol you created with a small number of people. Once the study has begun you don’t want to make changes to the protocol so piloting it can help you avoid that.
Step 5: Re-run the study on a regular basis
This is a benchmark study and it gives you a snapshot in time. It’s important to think about when it would make sense to re-run the study again. The more often you’re making changes to the product and experience, the less time you can wait between studies (quarterly or every six months). If the product and industry aren’t changing very often (unlikely if you’re at a startup) be responsible with customer time and keep them to an annual cadence.
What are common mistakes to avoid with benchmark studies?
Benchmarking at the wrong level
If you have a reasonably homogenous user base, you should benchmark your core experiences (think 80% of normal usage behavior). If you have multiple customer segments, benchmark the core user journey for each of those segments. If you have multiple product offerings, each with multiple customer segments, constrain your benchmark testing to either a single product offering or a single customer segment — whichever is most useful in terms of gathering the data you need to make useful decisions about the quality of the product.
Benchmarking at inconsistent intervals
In order to gather accurate benchmarks you’ll want regular, predictable snapshots of feedback. If you want to compare across benchmarking studies, you’ll need to be intentional about when you do so — either on a consistent schedule from a calendar perspective or a consistent schedule relative to product releases (e.g. always 1 month after a major update).
What are examples of benchmarking studies in action?
The Facebook Ads team ran an annual benchmark study to evaluate our core ads interfaces with different audience segments. We would often segment our advertisers by size/spend and goals (e.g. SMB advertisers, large ecommerce advertisers, brand advertisers, etc.) because they often had meaningfully different experiences on Facebook and used different parts of our product. We’d recruit 8-12 advertisers per segment for moderated usability studies that would include a short interview and a handful of tasks.
The output of these studies would be a scorecard that helped us understand how successful our customers were in completing the tasks with key areas of opportunity, in addition to “highlight reels” of customer usage. In concert with our own behavioral analytics and usage data, these studies provided the team with a solid picture of not just what our customers were doing in our products, but where they were and weren’t successful — often giving us a better sense of what our metrics represented. We’ll cover task success studies more later on in this newsletter.
What software can you leverage to help you with benchmarking studies?
If you’re digging into conducting a benchmarking study there is a lot of software that can help facilitate the various steps above, but you’ll have to piece several together to pull it off. Unfortunately, there is no single piece of software that covers every aspect of a benchmarking study end-to-end. Tools like SurveyMonkey and Qualtrics both offer benchmarking as a feature of their survey products to allow for easy comparison across similar products.
Net Promoter Score (NPS)
Ahh, NPS. Perhaps one of the most controversial QPD methods out there. You can find an equal number of people on both sides of the aisle from “NPS is useless” to “NPS is amazing.” At the very least you should know how to use it effectively!
What is NPS and when should I use it?
NPS is a single question survey instrument developed by Fred Reichfeld that asks respondents to rate the likelihood that they would recommend a company, product, or service to a friend or colleague. Respondents choose a number from 0 to 10, where responses of 9 or 10 are considered “promoters,” 7 or 8 are considered “passives,” and 0 through 6 are considered “detractors.” NPS scores are calculated by subtracting the proportion of detractors from the proportion of promoters (e.g. if you had 65% promoters, 10% passives, and 30% detractors, your NPS score would be 35).
While NPS is often used to measure a lot of things (incorrectly), it’s best used as a measure of evangelism within your user base (not satisfaction). Because the question asks about the degree to which someone would recommend your product, it’s most effective in evaluating the health of your word-of-mouth loops.
For a variety of reasons, NPS is often one of the earliest and most consistent self-report metrics that an organization tracks. This means that even if your organization uses NPS incorrectly, the way that product or business changes impact NPS scores can often help you contextualize those changes relative to historical changes since you have longitudinal NPS data.
What size and state of company should you consider leveraging NPS?
There’s no company size or state requirements, but if your product growth is almost entirely sales-led, NPS may not be a valuable metric for you to track since few people are likely to be evangelizing your product.
You shouldn’t worry about tracking NPS until you’re already tracking customer satisfaction and feedback, since satisfaction is usually a precursor to evangelism (though not necessarily – you can recommend a product that is the best solution to a problem, even if you aren’t highly satisfied with it).
How do I track NPS successfully?
Good news! NPS is one of the easiest metrics to track. You typically want to send two questions to a random sampling of your user base at a regular interval — the first being the standard NPS question and the second being “What is the primary reason for your score?” with an open-ended response.
It looks something like this:
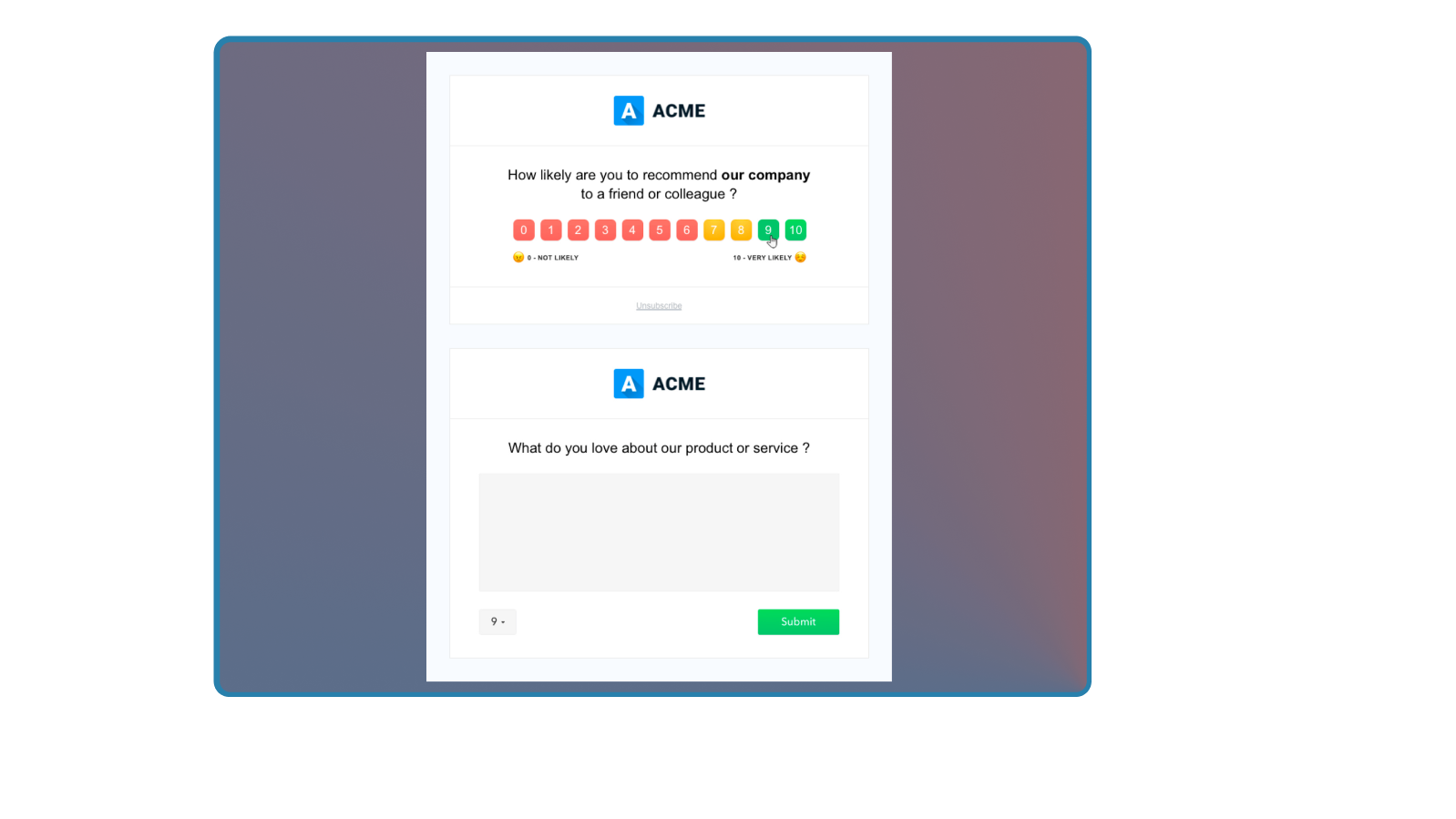
Common mistakes to avoid with NPS
This article highlights the most common NPS mistakes in detail, which are:
Using NPS to represent something it doesn’t
People often mistake NPS for a measure of retention or satisfaction, thinking that high NPS scores means you have satisfied, retained customers. Retention should be measured with retention curves and satisfaction should be measured directly through questions about satisfaction (see more below).
Measuring NPS incorrectly (at the wrong time or place)
People often trigger NPS surveys too early in a customer journey, before someone has completed at least one full habit loop and could meaningfully determine the degree to which they would recommend the product. Additionally, you often see NPS asked about specific features, which makes little sense because the features are not things you can recommend outside of using the product.
Other mistakes to avoid, not mentioned in that article:
Not segmenting users responding to NPS
If you have a self-service product, for example, you’ll have all kinds of users signing up for it. But if the product is targeting a specific user type or ICP and you look at all NPS responses you will get a really poor signal on the segments that matter. At Patreon we specifically targeted our NPS surveys at creators at or above a certain size. We knew that we weren’t building a product that would satisfy users under that size and therefore those NPS responses weren’t particularly useful to us.
Not engaging with your promoters and detractors
Just tracking your NPS isn’t enough unless you’re digging in to learn more. At both Patreon and Imperfect Foods I used NPS as an invitation to engage with a specific customer one on one. Reaching out to a detractor to understand why they won’t or can’t evangelize your product is a great starting point for qualitative user research. You can implement triggers that post NPS responses directly into a Slack channel and notify you when scores above or below a certain threshold are submitted and then follow up with those people.
What artifacts or templates exist that I can leverage to help me get better at NPS?
We’ll point you at one in particular which is the NPS question template from Qualtrics. But plenty of other tools, like SurveyMonkey also have helpful templates for starting your NPS journey.
What are examples of NPS in action?
At Slack, two of the most important surveys we had were our New User Survey (NUS) and Tenured User Survey (TUS). These went out to people who had been on Slack less than 30 days (NUS) and more than 180 days (TUS) and asked questions about satisfaction, how well Slack helped or hindered their core work responsibilities, and a number of other measures.
NPS was included on both of these surveys for a number of reasons. One was that it was one of the longest-running self report measures we tracked at the company (as mentioned above), which made it a helpful comparison point for other data. Another reason was that it provided a helpful compliment to questions we asked about satisfaction, performance, reliability, and product quality. Because we asked about all of these things, we could evaluate their relationship over time by comparing changes in one to changes in the other.
Finally, Slack is a multiplayer product, so while many people are required to use it for work, if you’re not excited about doing so, your actual Slack behavior is different. For us to be successful as a company, we knew that Slack couldn’t be a chore to use. Paying attention to NPS helped us evaluate people’s level of evangelism and correlate that to other aspects of the product experience so that we had a better sense of where to invest to deliver more value and a better experience to our customers.
What software can you leverage to track NPS?
So many! Almost every survey software has some version of this that you can use and there is simple software that is specifically designed for NPS tracking. Here are some examples:
Qualtrics
Medallia
Sprig
SurveyMonkey
Delighted
Retently
Customer Satisfaction or CSAT
What is a CSAT study and how should I use it?
Customer satisfaction (CSAT) is a measure of how “satisfied” a customer is with your product or service. This is often asked in some form of “How satisfied or dissatisfied are you with [product/service]?” followed by a 5 or 7 point scale that goes from “Very dissatisfied” to “Very satisfied.”
CSAT can be used in two different ways — one to gather immediate, time-sensitive feedback on a recent experience/interaction OR to gauge overall satisfaction with a product/service.
The former use case is often related to customer support interactions (e.g. How satisfied were you with the recent call you had with our support team?) or recently completed customer journeys (e.g. How satisfied were you with your purchase experience today?). In these situations, CSAT questions are often asked via a pop up/in-product experience that gathers feedback in the moment. They can also be asked over email as a follow-up.
Here’s an example of an email follow-up from a customer support interaction:
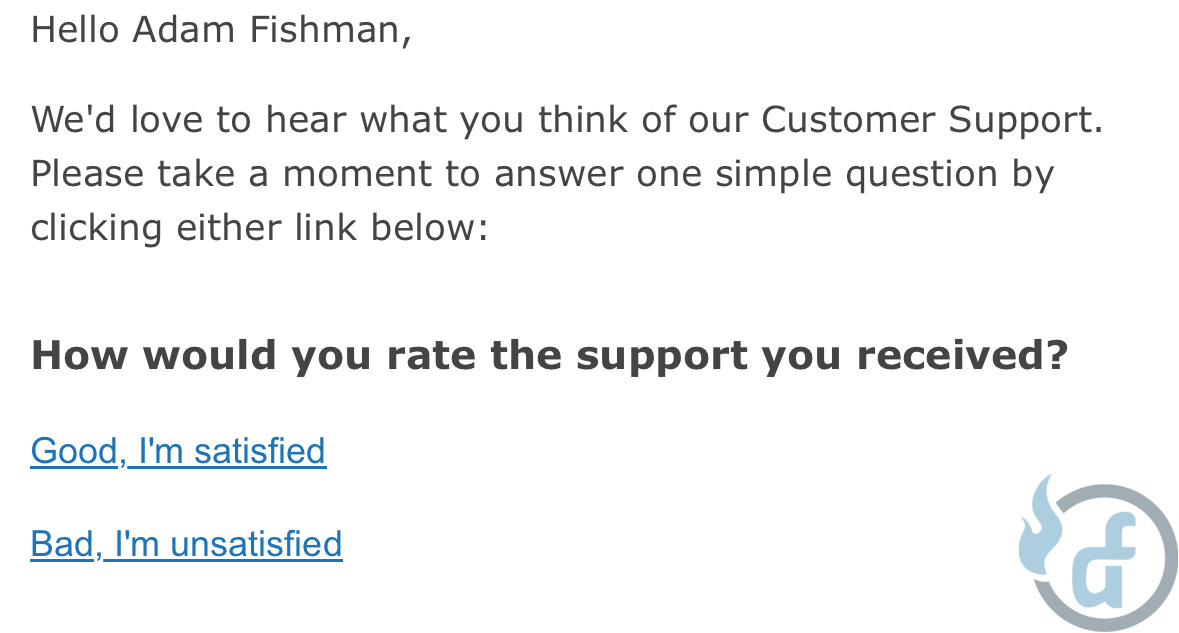
The latter use case (purchase experience) is more likely to occur on a tracking survey or similar assessment when you want to gather feedback on the customer’s satisfaction with the product at large.
What size and state of company should you consider leveraging CSAT?
Any size/state of a company can leverage CSAT questions. If you want to evaluate the quality of specific services/customer touch points, that can be a great time to use CSAT. Additionally, if you have a tracking survey, it’s possible you want to include an overall satisfaction question.
We recommend starting to track CSAT early in your lifecycle once you’re having meaningful interactions with customers. If you have a customer support team or person you should absolutely be tracking CSAT.
How do I successfully implement CSAT?
Asking about satisfaction is reasonably straightforward, and as we mentioned above, this often shows up as “How satisfied or dissatisfied are you with [product/service]?” The important part is to make sure that you’re not misconstruing the results of this question. If you’re asking about an overall product experience, you can report that X% of people are “satisfied” with the product, but you cannot say the same for specific features or areas of the product unless you asked for them. Attribute your results to the subject in question — the whole, not the parts.
While measuring satisfaction overall can be useful, satisfaction is most valuable when it’s connected to the drivers of satisfaction*.
Most times you want to ask about satisfaction, it’s worth asking yourself “If a customer was really satisfied with our product, what’s the best thing that they could say about us?” If you’re Slack, that might be “Slack increases the transparency of projects across my company.” or “Slack reduces the amount of meetings I have.” etc.
In this case, in addition to asking “How satisfied or dissatisfied are you with your overall Slack experience?”, you may also want to ask questions like:
How, if at all, has Slack impacted the transparency of projects, initiatives, or team activities across your company?
How, if at all, has Slack impacted the number of meetings in your typical work week?
These supplemental questions assume that transparency and meeting frequency (among other things) influence someone’s satisfaction, and asking about them helps you understand the degree to which they are correlated to satisfaction. This helps you identify which aspects of your product experience to invest in and which are already doing well — two things that customer satisfaction on its own cannot do.
*There is another survey type similar to CSAT called Customer Effort Score (or CES). It is an alternate way of measuring customer support satisfaction and instead measures the lengths to which a customer feels they need to go to resolve their issue.
What are common mistakes to avoid with CSAT?
Putting “very satisfied” first in your answer options
Whenever you ask about satisfaction, you should put the negative options (dissatisfied) first. This is both in line with how many survey scales are structured (lowest to highest) as well as helps combat a positivity bias that can exist with “very satisfied” being the first answer (which inflates your overall CSAT score).
Using a 3 point scale (dissatisfied, neither, satisfied)
If you’re going to ask about satisfaction, you should use either a 5 or 7 point scale so that you can include a degree of dis/satisfaction (i.e. somewhat satisfied). If you have a 3 point scale, respondents who don’t feel completely satisfied or dissatisfied will often leave neutral responses. There is nothing less helpful than a neutral response.
Inconsistency
Because CSAT is another form of benchmarking (against yourself or sometimes others in the industry) you want to make sure that you’re running it on a regular and recurring basis to spot trends and significant changes in the results.
Lack of follow-up
Much like with promoters and detractors, if you ask people to share their satisfaction (and they do) then it benefits you to follow up with those who are dissatisfied and, more occasionally, those who are very satisfied. Treat it as an invitation for qualitative discovery. As with NPS above, you can build the same set of triggers and pipe the information into a Slack channel.
What are examples of CSAT in action?
Slack has always taken customer support seriously. For a long time, Slack had a program called “Everyone Does Support,” where every employee would spend a week working as a part of the Customer Experience Team (CE) responding to issues and answering questions. While there were many things that made this team great, one of the big ones was how well they listened to feedback both about Slack and - more importantly - about their own service.
Customers of Slack who interacted with CE would often get a follow up email asking about their satisfaction with the interaction – something like “How satisfied were you with the recent call you had with our support team?”
The team cared both about whether people were satisfied and also why. If a customer clicked into the survey to respond, they were asked a few other questions about the experience:
“Were you able to successfully resolve the issue that you contacted support about?” with a yes or no response.
“Which of the following resources helped resolve your issue?” with answers including things like “a Slack employee,” “help center content” etc.
“What could we do to provide you with a better experience?”
The follow up questions depended on the type of issue that the customer had. All of them helped the team understand how the customer felt about the experience and how Slack best contributed to resolving (or at least trying to resolve) the issues. This helped the team determine where to invest more energy to improve the overall experience.
What software can you leverage to help you with CSAT studies?
Much the same as NPS, almost every survey software has some version of this that you can use. Here are some examples:
Qualtrics
Sprig
SurveyMonkey
Google Forms
Typeform
Looking for something specifically catered towards CSAT? Customer Thermometer and Nice Reply are options.
True Intent Studies
What is a True Intent Study and when should I use it?
We’re cheating a little bit here because True Intent Studies are a subcategory of surveys. But they’re unique enough and serve a specific purpose that we thought we should include them separately.
This type of survey is best used to understand why a visitor is coming to your site or product and whether they can accomplish their specific task. It’s different from a task completion or success exercise (another form of discovery we’ll cover below) because the visitor is telling you what the task they set out to accomplish is rather than you providing a series of tasks for them to complete.
You’re using true intent studies to understand elements of the user experience that are good or bad. You should use it when you want to know more about the goals of a user and whether they felt like they achieved them, but you also need to do this at a level of aggregated scale with a higher sample size to identify patterns.
The most analog version of this is the store owner who asks you “What brought you in today?” when you walk into the store. This is that behavior, but in an online setting.
What size and state of company should you consider leveraging a true intent study?
Just about any post product-market fit company can leverage a true intent study. Before you’ve reached that milestone it’s probably a waste of your time to get in the way of the small number of people coming to your site. As you grow and identify multiple entry points into your product, it can be quite helpful to know why people are showing up and whether they’re finding what they’re looking for.
This can also uncover a value proposition mismatch or a disconnect between your marketing promise and your product’s delivery of that promise.
How do you leverage true intent studies successfully?
True intent studies are inherently disruptive so it’s important to follow a few executional principles.
Step 1: Identify your objectives
Your primary objective should be to understand why they’re visiting and whether they are successful. If you’re looking to understand much more than that then you’re probably using the wrong discovery tool.
Step 2: Understand where you’re intercepting
You’ll want to trigger this intercept on specific pages or after certain interactions. Is it a specific landing page? When someone arrives with a specific URL parameter? Or when you identify that someone is a certain audience type through their behaviors on the site? Get clear on this up front.
Step 3: Create your questions and implement
You’ll want to ask visitors only a very few questions, specifically:
Are you okay with answering a few questions?
Why were you visiting today?
Did you successfully achieve your objective for this visit?
What feedback do you have?
Who are you-type questions (quick demographic information which is useful for segmentation)
Step 4: Analysis
You’ll want to hunt for trends in visit reasons—is everyone landing on this marketing page expecting something different than what you’re delivering? Are people who arrive via this one experience more or less successful than others who arrive via different avenues? Is this particular part of the experience really confusing for everyone who arrives?
What are common mistakes to avoid with true intent studies?
As I (Adam) mentioned above the true intent study is an intercept survey. It falls victim to all of the same mistakes we mentioned with surveying, like complexity, failure to pilot, poor segmentation, leading questions, etc. But the intercept-style survey is unique in one primary way: timing.
Avoid overly intrusive timing!
This probably deserves a rant* of its own but we’re already pretty deep on this article so I will just say that this is my personal pet peeve with intercept surveys. Have you ever been in the middle of doing something important on a website when an interstitial pops up asking you if you want to help them improve their experience? I hate this. Instead, load the survey request as a non-intrusive object in the corner or wait until your visitor has completed some core actions on the page before you pester them.
*I also hate this when asking you to review an app in the app store. Yes, I know that this is effective and gets people to do it, but it seems like I’m always in the midst of completing an important task when that thing pops up. And no, if you pop up in my face I am actually not enjoying my experience today and will probably not review you (or worse)!
What are examples of true intent studies in action?
At Patreon we were trying to understand the role that the “Browse Creators” experience played in a creator’s consideration process. It was creating some noise with creators because they thought it represented a leaderboard or discovery experience—neither of which were what we intended.
At the same time, we believe that a simple way to browse curated creators by category would help other creators decide if they should launch on the platform and provide inspiration for their own pages. There was a belief that this wasn’t happening and that it was primarily fans visiting the page hoping to find an interesting creator. This was more gut than fact so we decided to quantify it.
We ran a basic true intent study for visitors to that page asking them specific questions like:
Are you a creator? A fan? Both?
Why did you visit this page today?
Was your visit successful?
Through this study we were able to capture a lot of information about the makeup and intention of the visitors to that part of the experience. We learned that it was an equal mix of both creators and fans, that prospective creators were successful in what they sought out on that page, and that fans were not.
The knowledge we gained from this study led us to sunset this page and focus instead on bringing more integration of creator examples into the core site experience. It eliminated the noise from creators who thought the browse experience was for fan discovery, eliminated the dissatisfaction from fans who reached that part of the experience, and helped us bring the success that other creators experienced on that page (largely in information gathering for their consideration) into other areas of the site.
What software would you use to implement a true intent study?
We’ll skip the regular mentions of Qualtrics, SurveyMonkey, etc. and instead focus on a few tools that are uniquely well-suited for launching intercept surveys:
Hotjar
Qualaroo
Pendo - probably a bit of an overkill, but integrates nicely with the in-product experience
Task Success Rate
If you’ve ever heard feedback from customers that a product area is difficult to use or navigate then this analysis is for you!
What is task success rate analysis and when should I use it?
This is a quantitative usability testing analysis and is used to evaluate the effectiveness or efficacy of a specific set of tasks performed in a whole variety of contexts. You can use it as a pre/post measurement for usability changes you want to make in a specific product area. In this context you’re measuring how easy or difficult it is to complete various tasks like navigating to parts of the experience, finding and purchasing a product, or making changes to your account (to name a few).
What size or state should my company be to leverage Task Success Rate analysis?
As a qualitative method you can use it at any stage of a company because you’re using it directionally and don’t need a very large sample for that. If you are trying to develop a statistically valid change in task success you’ll need a large enough sample of data and that doesn’t make sense for smaller companies with fewer users.
If you are looking for a quantitative measure of ease of use and looking to build confidence in the role of usability testing at your company then you’re a good candidate for this product discovery method.
How do I leverage task success studies successfully?
Step 1: Define your Objectives and Tasks
The first step in the process is to very clearly define what you’re looking to learn. This might be something like the usability of an experience, how effective a feature or set of features are, or how satisfied users are with navigating an experience.
Step 2: Create Success Definitions
This is an area that is fraught with challenges because what constitutes “success” might vary across the different people consuming the results of this analysis. Some of the more common measures of success could be the time it takes on a task (“Can users figure out how to add a product to the shopping cart from the detail page in less than 1 minute?”) or error rate (“Did users make any unnecessary clicks along the way and have to hit the back button? If so, how many?”). It can also be whether a user was capable of executing the task at all (“When asked to look up their monthly earnings could users do it?”).
Step 3: Participant Selection
As with most QPD you want to make sure you’re including the correct population in your study. At a minimum you’ll want to select 5-10 users and if you want statistically significant results you’ll likely need many more. It’s important to segment across user types – are you looking at a new customer experience? Do you want to know if repeat users find it easier or harder following some usability changes? What about users who enter from a specific entry point, channel, etc.? All of these are dimensions that you can use to segment participants into.
Step 4: Conduct Study
There was a time when companies used to do these types of studies with makeshift (or legitimate) user research labs. Now these are done online through recorded interviews (see software examples at the end of this section).
Step 5: Analysis*
Your analysis will be based on how you’ve defined your definitions of success. If it’s “can someone complete the task” you calculate a rate by dividing successful completions by total attempts. If it’s something else like time on task then you’ll capture the amount of time it takes to complete an action and calculate ranges, median, max, min, etc.
*A note on pre/post analysis: Task success studies can either be used to analyze improvements to a particular experience OR they can be used to establish a baseline of opportunity (which might be limited and means you’ll only run the study once). If you’re using it to analyze improvements you’re running the study at least twice – once to establish that baseline and again after the changes (or during prototyping) to see if the changes were successful.
What are common mistakes to avoid in task success studies?
There are several obvious ones we hinted at above, such as not appropriately defining success criteria or selecting the wrong participants. Instead we’ll focus on the two less obvious mistakes that occur in this type of study.
Leading or influencing the participants
Inexperienced researchers (which can include product managers moonlighting as researchers) will inadvertently give away too much information or guide participants towards certain actions. This can come from a desire to avoid being wrong about your solution vs. seeking the truth. Your job in this type of QPD is to say as little as possible and only provide instructions.
Not balancing quant with qual
This is true of nearly all of the types of quantitative discovery we’ve outlined but because this type of study provides a forum for both data collection and qualitative feedback you don’t want to waste the opportunity. While you don’t want to steer the participants in a particular direction you do want to understand “why” they went down a specific path. This can be accomplished by asking them to think out loud while they are navigating or using the product.
What artifacts or templates exist that I can leverage to help me get better at task success studies?
I’m not trying to be a shill for Behzod’s Reforge program(s) but he has an entire module devoted to Usability Testing, including task success studies in his User Insights for Product Decisions program. Check it out. You can thank me later.
What are examples of task success in action?
At Patreon we had a creator analytics area that we knew creators had a lot of challenges with. We had built it on a whim in the earlier days of the platform to check a basic box and hadn’t reinvested the time and energy to make it navigable and user friendly.
But how do you measure whether improvements in the usability of the analytics experience are successful? Especially in a world where it’s difficult to tie those improvements to monetary outcomes. Task success is great for this!
Through conversation and surveying of creators we were able to gather the top tasks that they were looking to accomplish in the analytics area. We ran a task success study and were then able to quantify how difficult it was to find and complete those tasks (find their earnings for the last 6 months or identify their most popular posts, etc.). Turns out that most of those tasks were hard for them and our baseline was bad. Most couldn’t complete them.
We then redesigned and prototyped new structures and layouts for the analytics area. With each new prototype we’d run a follow-up task success study to see how we scored. By the time we released the updates we were at nearly a 100% success rate for the top tasks that creators came to perform. We subsequently also saw inbound customer support tickets related to this part of the product decrease substantially.
What software can you leverage to help you with task success studies?
Because task success is a derivation of overall usability testing you can use a lot of the same tools that you’d use to conduct that work and collect a larger sample.
Examples of online usability testing platforms include:
UserTesting
Maze
Userlytics
Lookback.io
Behzod’s Favorite Quantitative Product Discovery Success Story
We shared a lot of examples in this newsletter of quantitative product discovery in action. I asked Behzod to share one of his favorites to help us wrap up:
Going into 2018, one of Slack’s company priorities was improving the performance of desktop and mobile apps. Thanks to in-product analytics and instrumentation, Slack was aware of various issues that customers were having, but it didn’t have a systematic way to evaluate how these issues were perceived by customers or how they impacted their work.
Nicole Zeng—who led Quantitative Research (and taught Behzod most of what he knows about surveys)—partnered with Engineering leadership to build a survey instrument that would help the company know what issues were actually detected and how severely they impacted customers’ work. This is how the PRQ Tracking Survey (for Performance, Reliability, and Quality) was born.
The PRQ Tracking Survey asked questions like “How often, if ever, do you encounter the following while you are using Slack?” with answer options like “getting disconnected” or “temporary freezing or slowness.” As a follow up, the survey would ask about how much, if at all, those issues impacted someone’s ability to complete tasks that were a part of their everyday work.
While this survey provided valuable insight on its own into how Slack’s customers felt about various issues, in combination with in-product analytics, it gave Slack a nuanced view of how detectable and severe various issues were. This helped Slack calibrate the kinds of investments it needed to make in improving performance, reliability, and quality and avoid over-investing in defense.
The PRQ Tracking Survey ran through 2022, when various aspects of it were rolled into the broader customer tracking survey.
Conclusions / Wrap-up
We realize that this was a very, very long newsletter.
As Behzod said, “however long it took you to read it, just think how long it took us to write it!”
We aimed to provide a canonical reference and solid starting point for the universe of quantitative product discovery that you might need to conduct as a product manager.
This should also be a helpful resource for marketers, researchers, designers, and anyone else who wants to improve at quantifiable user research and become a better builder.
One thing you always hear as a Product Manager is “talk to customers!” We provided some examples of where quantitative and qualitative discovery come together in this article. In the next and final newsletter on Mastering Product Discovery we’ll share the canonical resources on qualitative product discovery. That’s the talking and listening part.
Until next time!

Like it. Good work, especially the added perspective on common mistakes.